监控可视化——Grafana
上一篇笔记中,我们使用了kube-prometheus快速在集群内部署了一套prom监控全家桶,它可以全自动地用node-exporter、kube-state-metrics、cadvisor等组件对集群暴露的各个维度的数据进行抓取。那么在抓取数据后,假如我们希望把它们进行可视化,做成数据大屏,这个时候,全家桶自带的grafana就派上用场了。
使用kubectl -n monitoring get deployments 我们可以发现grafana的deployment已经被安装到命名空间中,此时只需要跟prometheus一样使用NodePort Service把pod与节点网络打通,就能从外部访问grafana的web应用了,默认密码当前版本是admin/admin,登陆后就可看见欢迎界面:
在menu→dashboard,可以看见已经配置好了很多面板:
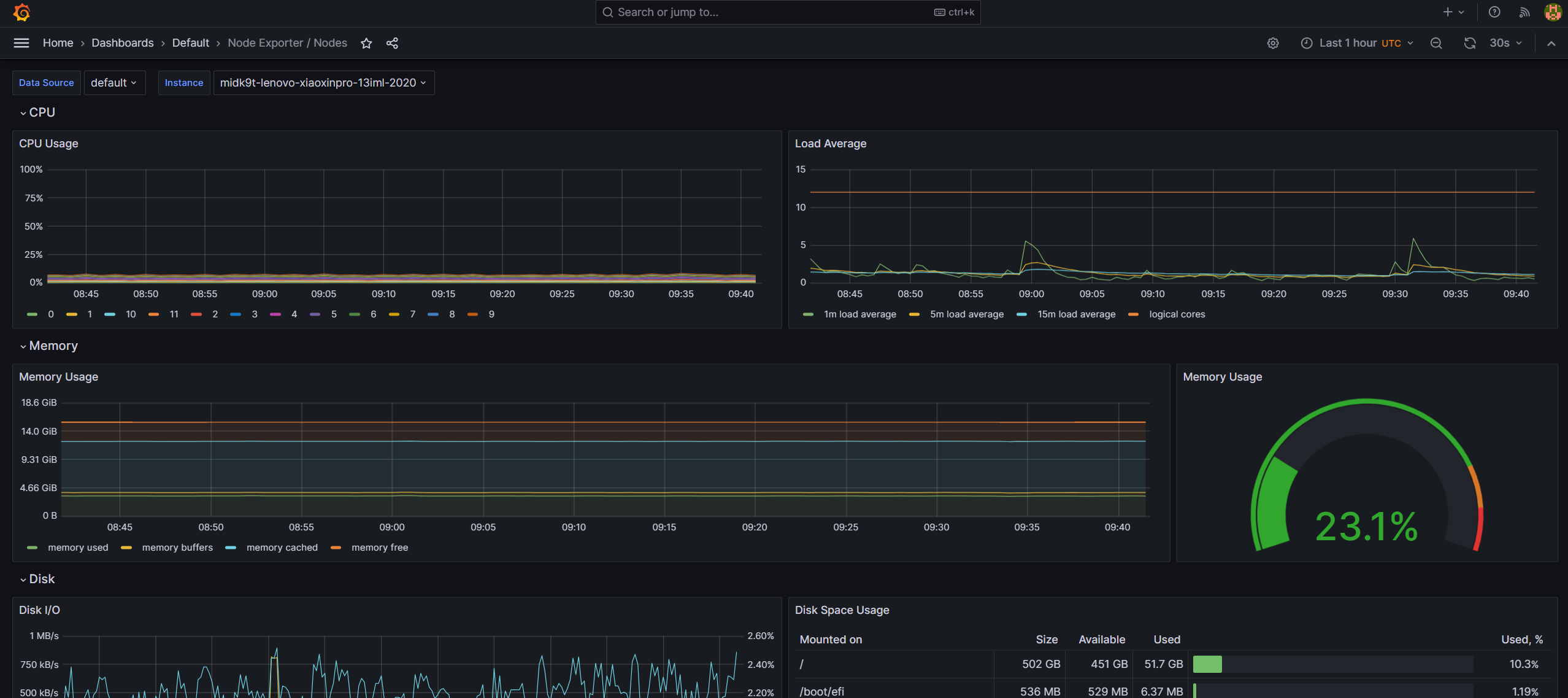
看看node-exporter的面板:
接下来我们使用上回介绍的常用指标,做一个general dashboard,在新建dashboard的界面,点击add visualization,然后填入对应的promQL并应用,最终得出:
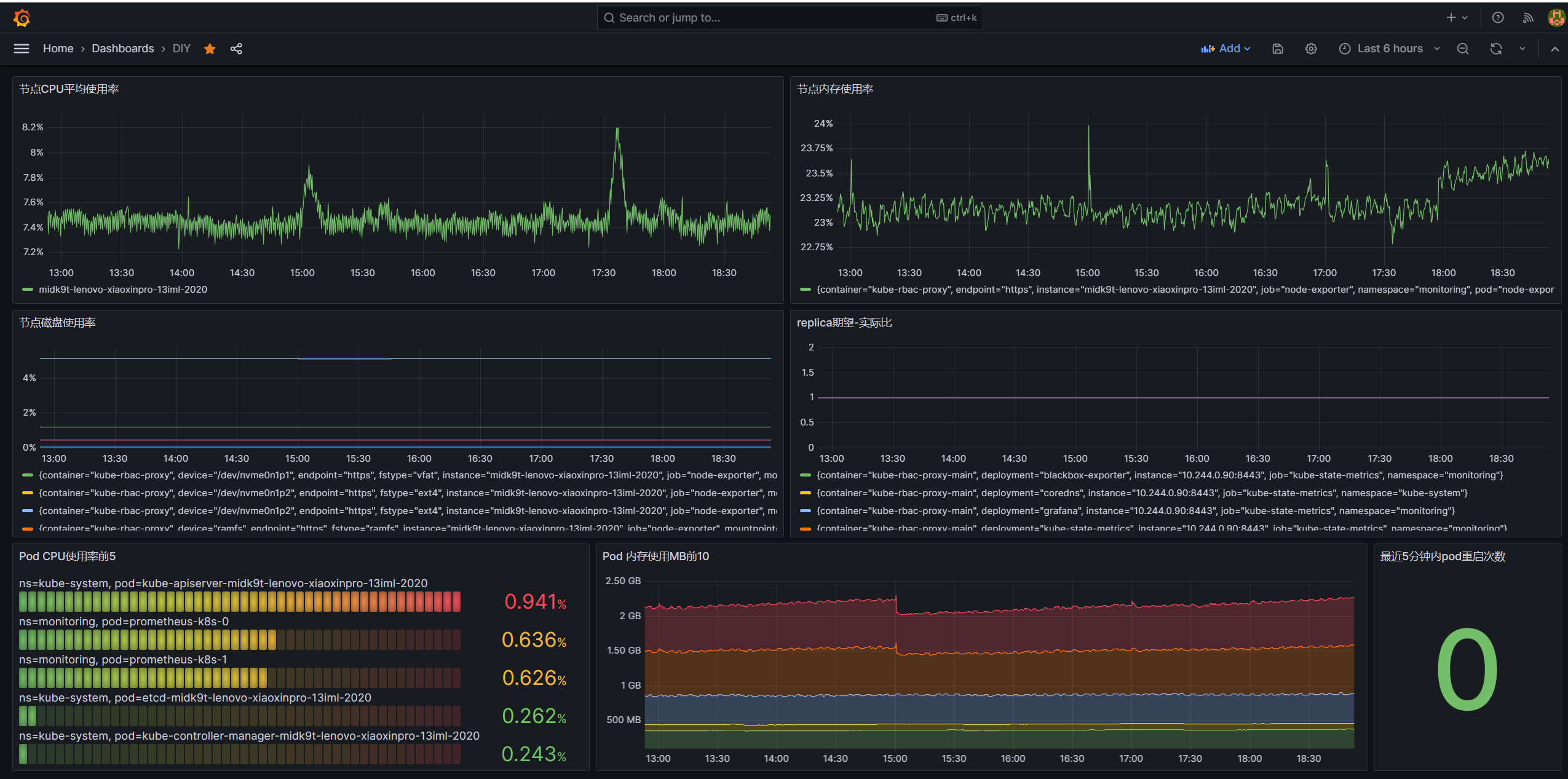
通过这个基础面板,我们可以得知一个集群节点各维度的基本状况,接下来,我们来重点探索一下Prometheus的告警能力
告警——PrometheusRule与alertmanager
Alerting overview | Prometheus
alertmanager是Prometheus监控生态中专门负责处理告警的组件,Prometheus根据配置文件定义的alerting rule,对满足告警条件的事件生成告警,然后推送至alertmanager,而alertmanager则负责对这些告警进行分组、静默与转发至第三方推送。在kube-prometheus安装的时候,它便自带了许多prometheus alerting rules:
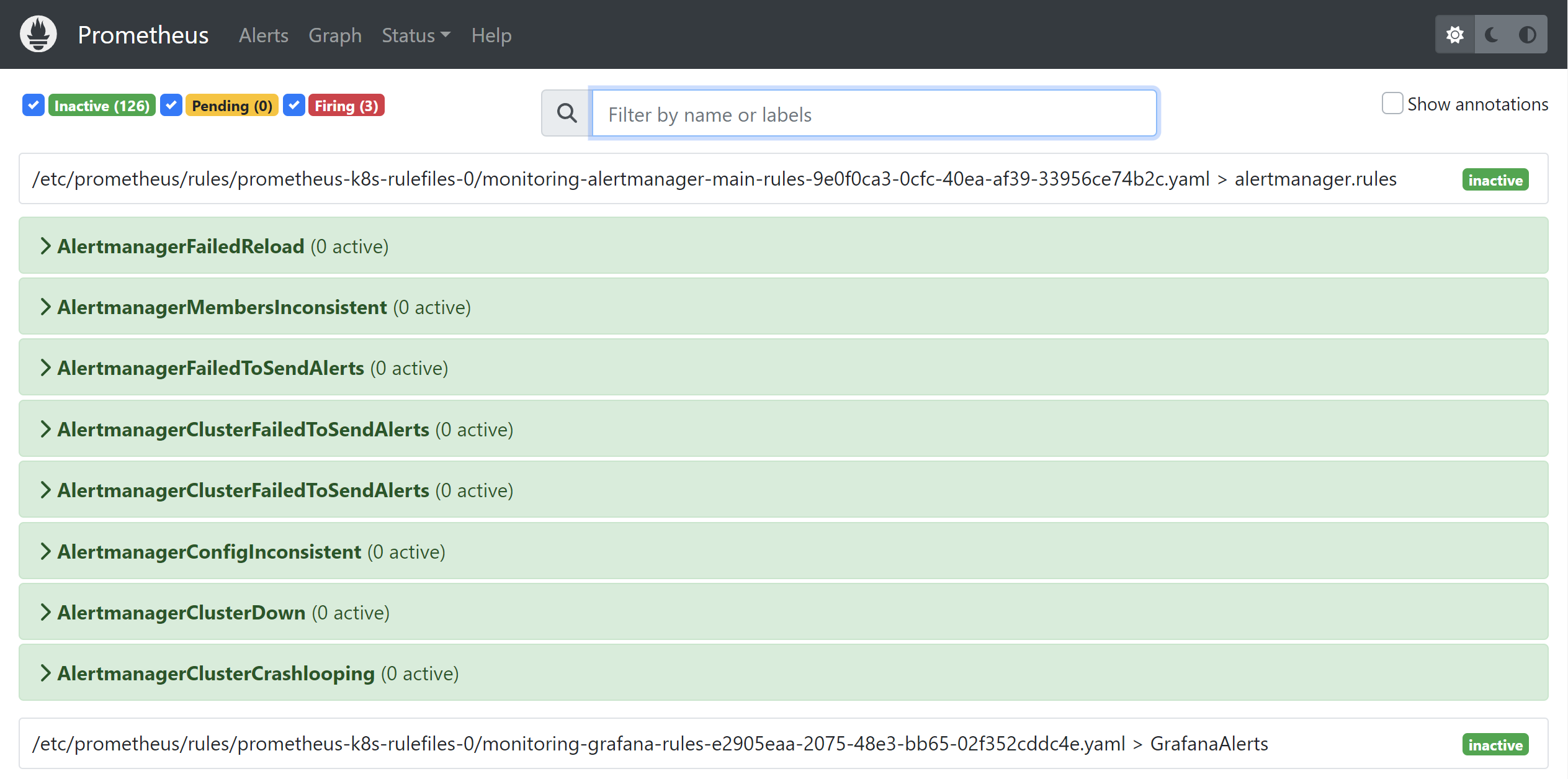
在原生Proemtheus中,rule是配置在config文件中的,而在Prometheus Operator中,则是由PrometheusRule CRD来负责管理,kube-prometheus自带了许多PrometheusRule的yaml文件,如nodeExporter-prometheusRule.yaml、kubeStateMetrics-prometheusRule.yaml等。Operator会监听这些文件的内容,生成对应的rule config文件,然后加载到Prometheus中,下面是一个PrometheusRule CRD例子,它在磁盘空间不足15%的时候会触发:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
labels:
app.kubernetes.io/component: exporter
app.kubernetes.io/name: node-exporter
app.kubernetes.io/part-of: kube-prometheus
app.kubernetes.io/version: 1.7.0
prometheus: k8s
role: alert-rules
name: node-exporter-rules
namespace: monitoring
spec:
groups:
- name: node-exporter
rules:
- alert: NodeFilesystemSpaceFillingUp
annotations:
description: Filesystem on {{ $labels.device }}, mounted on {{ $labels.mountpoint }}, at {{ $labels.instance }} has only {{ printf "%.2f" $value }}% available space left and is filling up.
runbook_url: https://runbooks.prometheus-operator.dev/runbooks/node/nodefilesystemspacefillingup
summary: Filesystem is predicted to run out of space within the next 24 hours.
expr: |
(
node_filesystem_avail_bytes{job="node-exporter",fstype!="",mountpoint!=""} / node_filesystem_size_bytes{job="node-exporter",fstype!="",mountpoint!=""} * 100 < 15
and
predict_linear(node_filesystem_avail_bytes{job="node-exporter",fstype!="",mountpoint!=""}[6h], 24*60*60) < 0
and
node_filesystem_readonly{job="node-exporter",fstype!="",mountpoint!=""} == 0
)
for: 1h
labels:
severity: warning
|
它被operator动态生成于prometheus pod的这个地方:

值得一提说的是,社区还维护了一个web手册来解释kube-prometheus配置的告警含义,原因与维护手段等,看到有不认识的指标发生告警了,可以上去查找:
Introduction
alertmanager
如上所述,prometheus负责基于指标与数据生成告警,仅此而已,在实际场景中,我们还需要一个专门的工具来处理这些告警,对它们进行分组,发送到不同的团队等,alertmanager就是负责这件事情的专家,下面是一个alertmanager的配置主要组成:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
global:
[ resolve_timeout: <duration> | default = 5m ]
[ smtp_from: <tmpl_string> ]
[ smtp_smarthost: <string> ]
[ smtp_hello: <string> | default = "localhost" ]
[ smtp_auth_username: <string> ]
[ smtp_auth_password: <secret> ]
[ smtp_auth_identity: <string> ]
[ smtp_auth_secret: <secret> ]
[ smtp_require_tls: <bool> | default = true ]
[ slack_api_url: <secret> ]
[ victorops_api_key: <secret> ]
[ victorops_api_url: <string> | default = "https://alert.victorops.com/integrations/generic/20131114/alert/" ]
[ pagerduty_url: <string> | default = "https://events.pagerduty.com/v2/enqueue" ]
[ opsgenie_api_key: <secret> ]
[ opsgenie_api_url: <string> | default = "https://api.opsgenie.com/" ]
[ hipchat_api_url: <string> | default = "https://api.hipchat.com/" ]
[ hipchat_auth_token: <secret> ]
[ wechat_api_url: <string> | default = "https://qyapi.weixin.qq.com/cgi-bin/" ]
[ wechat_api_secret: <secret> ]
[ wechat_api_corp_id: <string> ]
[ http_config: <http_config> ]
templates:
[ - <filepath> ... ]
route: <route>
receivers:
- <receiver> ...
inhibit_rules:
[ - <inhibit_rule> ... ]
|
其中:
- global为一些全局适用或者默认参数
- templates定义了告警通知使用的模板
- route定义了按label分类的路由
- receivers定义了通知方的信息
- inhibit_rules设置了抑制告警的规则
在这些组成里面,重点是route,下面是route的一个例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
route:
receiver: 'default-receiver' #发往default-receiver
group_wait: 30s #特定group有新告警的时候,等待30s再集体发送
group_interval: 5m #发送同一组告警的下一个通知之前的等待时间
repeat_interval: 4h #成功发送警报后,相同的警报再次被发送之前需要等待的最小时间间隔
group_by: [cluster, alertname] #以(cluster, alertname)这个标签元组作为分组依据
routes:
- receiver: 'database-pager' #匹配server~=mysql|cassandra的标签的告警发给database-pager
group_wait: 10s
match_re:
service: mysql|cassandra
- receiver: 'frontend-pager' #匹配team=frontend的标签的告警发给frontend-pager
group_by: [product, environment]
match:
team: frontend
|
告警实战
接下来,我们来实现一个简单的实战demo,设置一个简单的告警规则,并让它在触发的时候发送至gmail吧
实现简单实用的ac exporter
由于我的自建集群是运行在一台笔记本上的,虽然这让这个集群天生自带了备用电源,但我还是得确保我能第一时间知道它的电源线断掉了,正在使用电池。基于这一实际需求,我们这次就来实现一个检测主机电源是否连通的指标吧。
首先我们来写一个在node宿主机上运行的ac exporter go应用,它负责不断调用acpi这个命令,去检测我的小新pro13笔记本是不是还连着电源,然后使用Prometheus官方库,暴露Prometheus能直接抓取的接口:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
|
package main
import (
"os/exec"
"time"
"net/http"
"log"
"github.com/prometheus/client_golang/prometheus"
"github.com/prometheus/client_golang/prometheus/promhttp"
)
func acConnected() bool {
_, err := exec.Command("sh", "-c", "acpi -a | grep 'Adapter 0: on-line'").Output()
if err != nil {
return false
}
return true
}
func main() {
hostbytes, err := exec.Command("hostname").Output()
if err != nil {
panic(err)
}
hostname := string(hostbytes)
reg := prometheus.NewRegistry()
var acMetric *prometheus.GaugeVec = prometheus.NewGaugeVec(prometheus.GaugeOpts{
Name: "node_ac_adapter_connected",
Help: "1 means power adapter is connected to node machine, 0 elsewise",
}, []string{"instance"})
reg.MustRegister(acMetric)
go func() {
for {
connected := 1
if !acConnected() {
connected = 0
}
acMetric.With(prometheus.Labels{"instance": hostname}).Set(float64(connected))
time.Sleep(1 * time.Second)
}
}()
http.Handle("/metrics", promhttp.HandlerFor(reg, promhttp.HandlerOpts{Registry: reg}))
log.Fatal(http.ListenAndServe(":5333", nil))
}
|
编译并运行后,这个exporter便会每秒检测电源适配器是否连接,然后暴露成/metrics接口,供Prometheus抓取:

当拔开电源后,node_ac_adapter_connected这个暴露的Gauge值就会变为0:

实现完ac exporter后,我们还需要想办法让集群内的Prometheus能够访问这个链接,这里我们参考kube-prometheus中node-exporter的实现,使用一个hostNetwork: true的kube-rbac-proxy daemonset,它负责代理Prometheus的请求到宿主机的5333端口,然后我们为这个daemonset建立一个集群内的Service,最后配置ServiceMonitor来让Prometheus访问这个daemonset:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
|
apiVersion: apps/v1
kind: DaemonSet
metadata:
labels:
app.kubernetes.io/component: exporter
app.kubernetes.io/name: ac-exporter
name: ac-exporter
namespace: monitoring
spec:
selector:
matchLabels:
app.kubernetes.io/component: exporter
app.kubernetes.io/name: ac-exporter
template:
metadata:
labels:
app.kubernetes.io/component: exporter
app.kubernetes.io/name: ac-exporter
spec:
hostNetwork: true
containers:
- image: quay.io/brancz/kube-rbac-proxy:v0.15.0
name: ac-exporter-proxy
args:
- --upstream=http://127.0.0.1:5333/
---
apiVersion: v1
kind: Service
metadata:
name: ac-exporter-svc
namespace: monitoring
labels:
app.kubernetes.io/component: exporter
app.kubernetes.io/name: ac-exporter
spec:
ports:
- name: ac-exporter-port
port: 5333
targetPort: 5333
selector:
app.kubernetes.io/name: ac-exporter
clusterIP: None
---
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
labels:
app.kubernetes.io/component: exporter
app.kubernetes.io/name: ac-exporter
name: ac-exporter-sm
namespace: monitoring
spec:
endpoints:
- interval: 15s
port: ac-exporter-port #注意这个port是指service中port的name
relabelings:
- action: replace
regex: "(.*)"
replacement: $1
sourceLabels:
- __meta_kubernetes_pod_node_name
targetLabel: instance
jobLabel: app.kubernetes.io/name
selector:
matchLabels:
app.kubernetes.io/component: exporter
app.kubernetes.io/name: ac-exporter
|
把这份组合yaml应用到集群后,等待operator加载进Prometheus,我们就能看到这个自定义指标出现在Prom里面了:

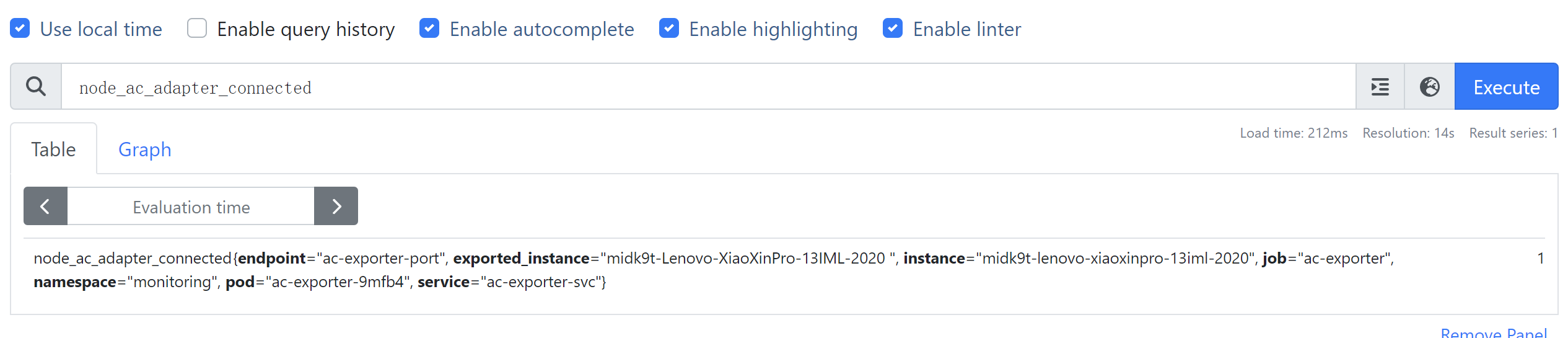
配置PrometheusRule
接下来,我们来使用PrometheusRule CRD来配置一条告警,在node_ac_adapter_connected这个指标消失了,或者等于0,超过1分钟时触发:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
labels:
app.kubernetes.io/component: prometheus
app.kubernetes.io/instance: k8s
app.kubernetes.io/name: ac-exporter
prometheus: k8s
role: alert-rules
name: prometheus-k8s-ac-exporter-rules
namespace: monitoring
spec:
groups:
- name: prometheus
rules:
- alert: PowerAdapterDisconnected
annotations:
description: The power adapter is disconnected and currently using batteries.
summary: Power disconnected.
expr: |
absent(node_ac_adapter_connected) or node_ac_adapter_connected == 0
for: 1m
labels:
severity: critical
|
应用后可以在prometheus管理页面的status→rules里面看到:

此时假如我们kill掉节点上的ac_exporter进程,等待1分钟,便能在管理页面上面见到告警触发了:
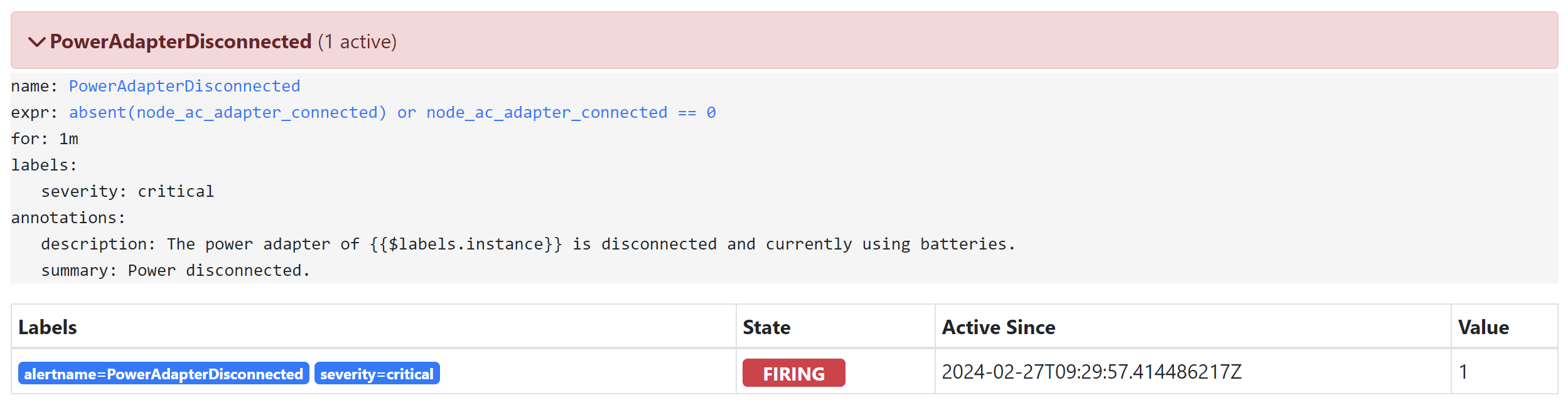
配置Alertmanager
现在我们已经能触发告警了,还需要配置alertmanager,使它知道要转发到gmail,有多种方法配置受prometheus operator管理的alertmanager,kube-prometheus默认是用secret的方式,我们把相关配置加进去默认的secret yaml,然后apply就可以了:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
stringData:
alertmanager.yaml: |-
# ...
"receivers":
- "name": "gmail"
"email_configs":
- "to": "xxxxx@gmail.com"
"from": "xxxxx@gmail.com"
"smarthost": "smtp.gmail.com:587"
"auth_username": "xxxxx@gmail.com"
"auth_identity": "xxxxx@gmail.com"
"auth_password": "xxxxxxxx"
"send_resolved": true
"route":
"group_interval": "5m"
"group_wait": "30s"
"receiver": "Default"
"repeat_interval": "12h"
"routes":
# ...
- "matchers":
- "severity = critical"
"receiver": "gmail"
|
验证效果
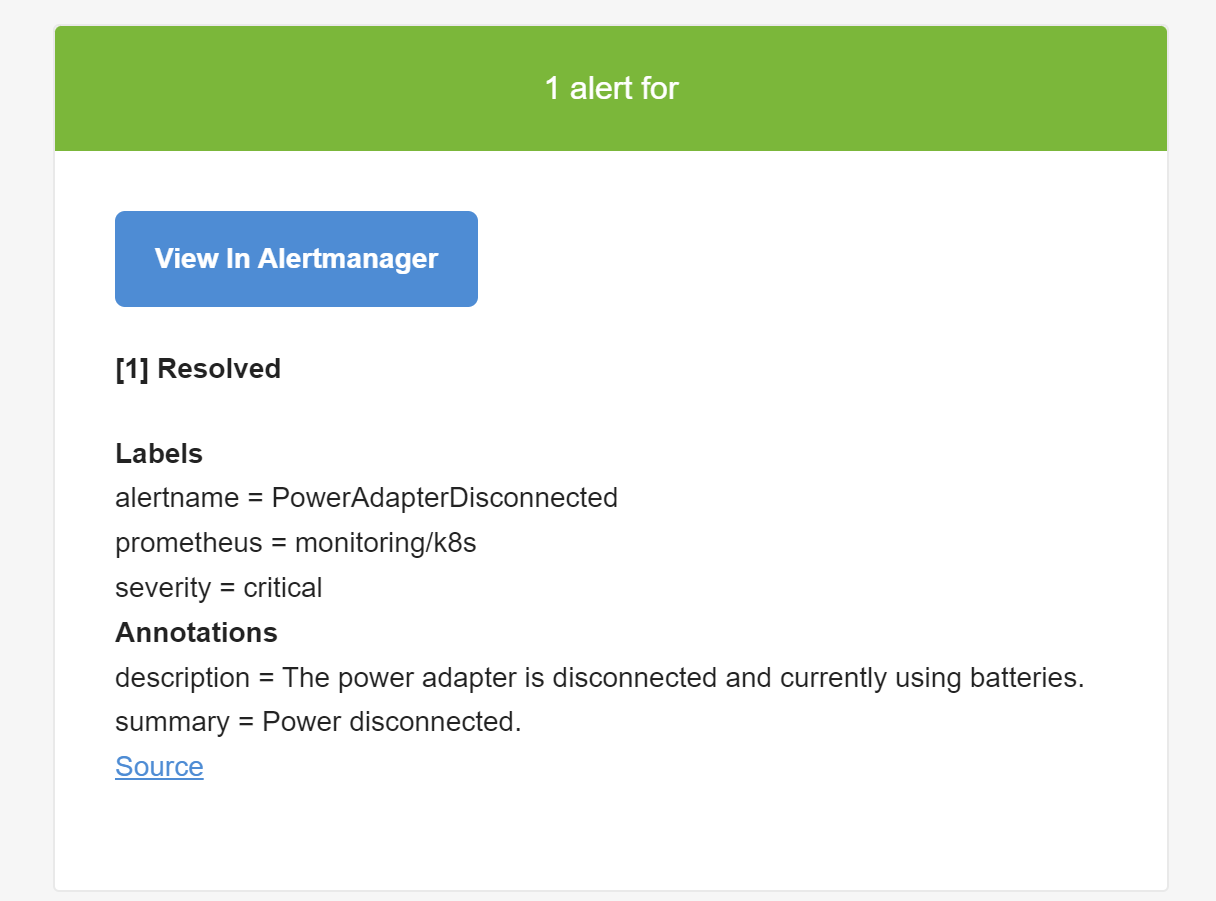
现在我们再次把ac_exporter进程杀掉来触发告警,稍等片刻,就能收到来自Gmail的告警邮件:
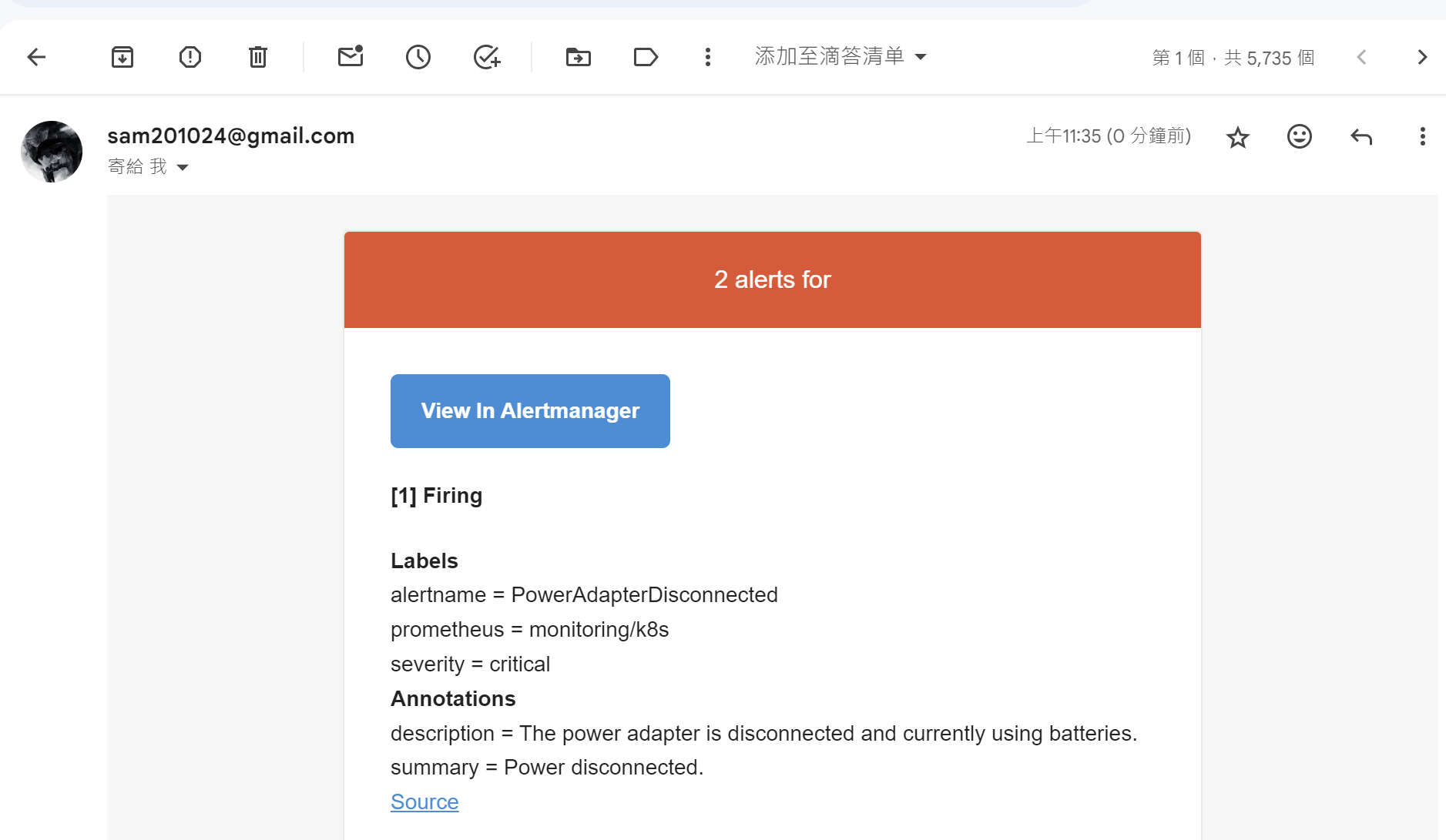
把ac_exporter重新启动,就能收到告警解除的邮件:
May Be Continued
在这篇笔记中,我们记录了如何用grafana实现监控数据可视化,以及如何在k8s上的Prometheus中配置告警与推送,最后实现了一个把电源中断事件推送至Gmail的demo。到目前为止,我们已经对Prometheus的使用进行了相对全面的入门介绍,接下来有空的话,下一篇就探讨一下Prometheus治理上的内容吧,比如说监控数据的持久化,组件的高可用等。